The release of vSAN 6.6 came with a tremendous ‘what’s new feature set’ brining VMware’s software-defined storage and hyper-converged solution to the next level. Many bloggers out there in the community did a great to job to explain the details of the following new features:

- Removal of the Multicast requirement
- Encryption using existing KMS solutions (KMIP 1.1 compatible)
- Stretched Cluster enhancements (changing of witness hosts and secondary level of failure protections within a site)
- Re-synchronization enhancements (including throttling)
- Web Client independant vSAN monitoring User Interface
- Performance enhancements
- Maintenance Mode enhancements including more information and prechecks
- New ESXCLI commands (that can be used with PowerCLI, e.g. to easily get smart data of the physical devies)
- and many more…
How do I get vSAN 6.6?
It is part of the vSphere 6.5d release. Check the vSAN release notes. Update vCenter to 6.5d and upgrade your ESXi hosts to vSphere 6.5d.
Since people don’t always read release notes (really…you should!!!) I quote the following section.
vSAN 6.6 is a major new release that requires a full upgrade. Perform the following tasks to complete the upgrade to vSAN 6.6:
Upgrade the vCenter Server to vSphere 6.5.0d. For more information, see the VMware vCenter Server 6.5.0d Release Notes.
Upgrade the ESXi hosts to vSphere 6.5.0d. For more information, see the VMware ESXi 6.5.0d Release Notes.
Upgrade the vSAN on-disk format to version 5.0.
Note: Direct upgrade from vSphere 6.0 Update 3 to vSphere 6.5.0d and vSAN 6.6 is not supported.
What I am going to do is try to figure out what I expect from a the vSAN release (based on the project-experienced gathered over the last years) and in which cases vSAN 6.6 (might) meet or lack those expectations.
vSAN Pain-Points in the past:
- Multicast requirement for the network
- Inefficient reprotect/resync/data-migration handling
- Certified Hardware, Firmware, Driver ‘brutality’
- Web Client dependancy
- Secondary Level of Failures to tolerate in a stretched Cluster
- Absent component resync interaction within User Interface & Alert behaviour
I have been able to work with vSAN in multiple scenarios. I gained a lot of experience in homelab situation (nested and physical) or at customers sites. Customers that had critical and non-critical workload in all-flash/hybrid stretched and non-stretched installations.
Multicast requirement for the network
That’s the good old discussion everyone hates to have with the networking team. VMware folks know that very well from NSX and vSAN. We need multicast capability. The reaction is always nearly identical: No one likes multicast.
Even though we typically deal with Layer-2 multicasts in vSAN (which are easier to implement and deal with than Layer3 multicasts), it comes with an added network dependancy and therefore complexity. Summarized within vSAN multicasts are used to figure out which vSAN/ESXi-nodes are part of the cluster.
This behaviour has changed with vSAN 6.6. As soon as all Cluster-nodes are updated to the latest version the dependancy of multicasts is gone. Cluster-membership information are managed and updated via the vCenter Server. Taking away the control-plane from network and give it to the vCenter is for sure something most of us will prefer. On the other side we need take care about additional operational tasks in case the vCenter is absent (and new Hosts are added to the Cluster). The rise of a resilient vCenter Server Appliance (including Backup and High-Availability mechanisms) and the fact that it becomes a tightly coupled component (using distributed switches, NSX and other solutions) that must be high-available, reliable and recoverable makes switch from multicast-managed to vCenter-managed cluster membership information acceptable.
Inefficient reprotect/resync/data-migration handling
This is a pretty serious topic in my opinion. vSAN works great during normal (even high-IO intensive) workloads. The latency is in most cases pretty constant with less (positive and negative peaks) and a low standard-deviation. But there are situation that really gave me head-aches over the past years.
Data resyncs can occur after Full-Data Migration (going into maintenance mode) or hardware-failures. The amount of data that needed to be resynced was quite hard to determine upfront. I observed multiple times that putting an ESXi host with 3.6TB capacity SSDs into the maintenance-mode with full-data migration. Since the used capacity was < 60% on the capacity devices I would have expected a maximum resync data of around 2TB. Instead I observed it to be around 5-6TB.
The duration/speed of such a resync is also quite fluctuating. Sometimes I have observed via ESXTOP a network transfer of around 1500MBit/s, sometimes the number was never pushing more than 300MBit/s which ended up in nearly endless resync operations (even though the overall IO/latency behaviour of the workload was really low).
The next thing I observed multiple times (especially in homelab / not-certified environments) is that this resync operation might lead to hanging / non-responsive ESXi hosts and therefore a vSAN Cluster disaster. The reason seems to be found in the de-staging process from the write-buffer onto the capacity disks. Every write operation is logged within vSAN, filling up this log can lead to such a severe situation and a high congestion-value within the metrics/log files. Multiple patches within the last releases of vSAN had attempts to deal with that problem.
Since this problem should have been addressed with the latest vSAN hotfix, vSAN 6.6 promises to address the resync efficiency:
-
Rebalancing and repair enhancements. Disk rebalancing operations are more efficient. Manual rebalancing operation provides better progress reporting.
-
Rebalancing protocol has been tuned to be more efficient and achieve better cluster balance. Manual rebalance provides more updates and better progress reporting.
-
More efficient repair operations require fewer cluster resynchronizations. vSAN can partially repair degraded or absent components to increase the Failures to tolerate even if vSAN cannot make the object compliant.
I am definitely looking forward to analyze the new behaviour here in vSAN 6.6 since from a pure subjective feeling that was something Nutanix always did much better within it’s solution.
Certified Hardware, Firmware, Driver ‘brutality’
Not much more to add here: Using non-certified devices, drivers, firmware might lead to a vSAN catastrophe. I assume this behaviour hasn’t changed. vSAN is storage software meant for the enterprise. Use certified controller and devices (SAS ftw) with high queue-depths to ensure proper performance and stability.
Web Client dependancy
There were always some statements when I talked about vSAN in my classes. One of those sentences was: “Never trust the Web Client”. vSAN could only be managed from within the vSphere Web Client, which had from time to time some severe update or content issues. Sometimes the health-service was not properly displayed, sometimes it took minutes to load something, sometimes it told us that there is no resync in place while 10 TB of data was transferred over the network.
I just didn’t trust it and that’s why we have learned to work with the Ruby vSphere Console (RVC). There are a lot of useful commands in there to figure out more the existing cluster situation.
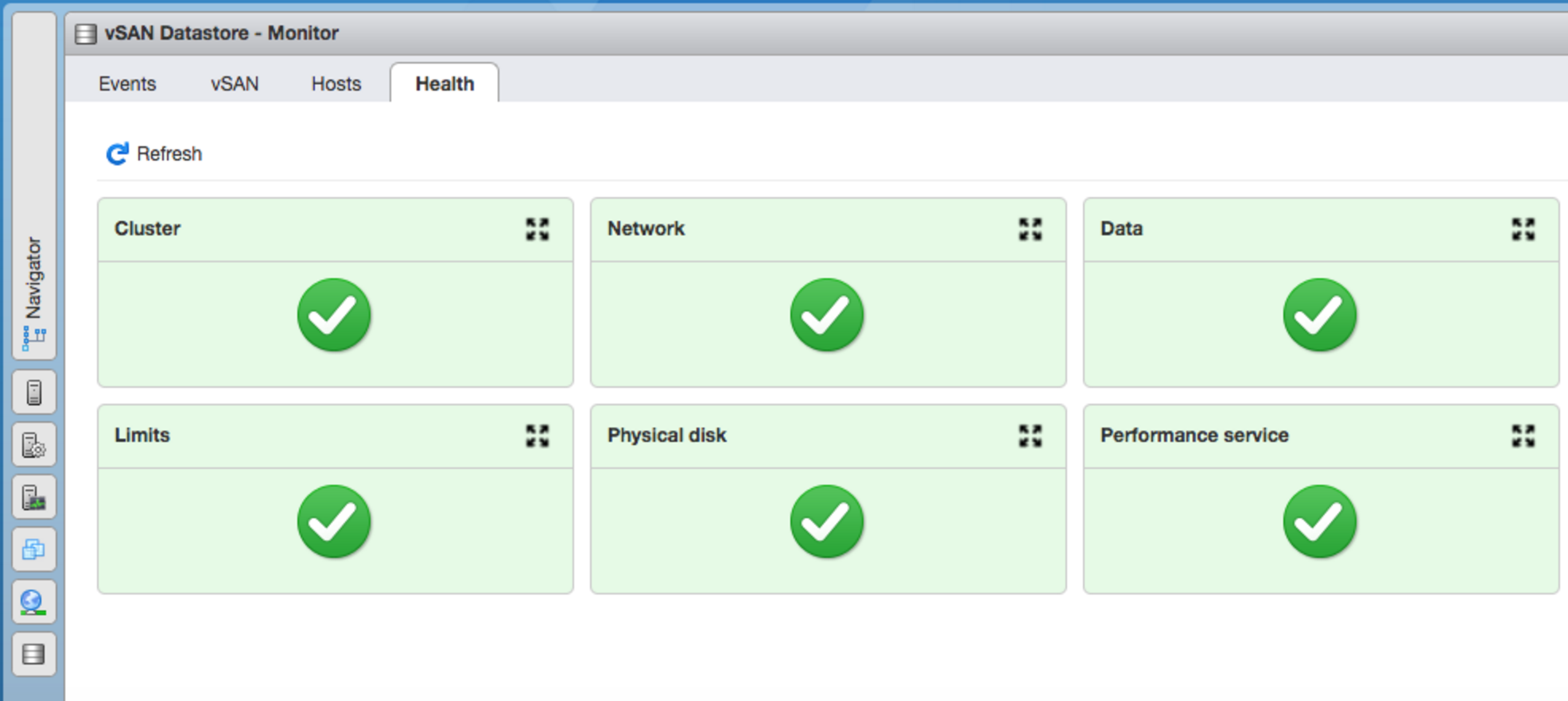
Within HTML5 based ESXi host client there is now a vSAN Section that gives you information about the cluster (e.g. its health state) without the need of the lazy Adobe Flex/Flash based Web Client (Even though the 6.5 flex based client has made huge improvements).
Secondary Level of Failures to tolerate in a stretched Cluster
Stretched Clusters are really something many businesses want (even though the might not even need it). For sure a stretched vSAN Cluster has its charm. One thing I always struggled with, was that the RAID1 component protection across site was the only way of protection the storage objects (like a VMDK). So if there is a site maintenance there was no way that components within one site were protected during this time-window. A failure of a single host during such a window might have lead at least to some data-loss of the affected components.
This risk can now be mitigated by having nested fault domains within a site. Within the VM Polciies we can now define Primary Level of Failures to tolerate (PFTT, e.g RAID1) and Secondary Level of Failures to tolerate (SFTT, e.g. RAID 1/5/6).
This is quite an enhancement that comes in parallel with Site-Affinity settings (in which site a FTT=0 object should reside) and witness operations within the Web Client User Interface (migrate to new witness).
Absent component resync interaction within User Interface & Alert behaviour
One thing I am still missing is an interactive way in case VMDK objects are absent. In that case by default vSAN will wait 60 minutes until a resync takes place. This value can be changed via an advanced ESXi setting. Anyway that is a behaviour people should be aware of. I would prefer some kind of interactivity in the User Interface that shows the countdown when a resync of the data is going to occur. Maybe you did further actions that take around 70 minutes and you don’t want to stress your environment additionally with those resync operations (remember my statement about the resync stress in the past). Wouldn’t it be cool to just be able to click on wait + 15minutes (like the snooze option on your smartphone) with in the user interface if you know the vSAN component will come back in a short amount if time. The same interface could be used for a repair immediately function.
The other I didn’t really like in the past was the behaviour of vCenter alerts in case of planned maintenance tasks/reboots. Doing a vSphere update in a vSAN Cluster ends during the reboot phase with a bunch of many alerts that are triggered. IMO one non-critical warning would be enough .
Ok ok I know this is something for a feature request :) I should properly add this up as well.
Summary
vSAN has come a long road and this release seems to really fix many of the things I have complaint about in the past. The next 6 months will show if it will really keeps up the promises it has given. I am really looking forward to give an update here.
Links:
Hi Fabian, nice post. Goes hand in hand with my observations.
Did you think about how to ensure equal storage utilization of both sites in a stretched cluster if you are using site affinity, FTT=0?
It’s a very nice feature to my mind, but still rises a lot of questions.
Good question. Haven’t though about it so far since I nearly never used FTT=0 so far… I would assume it will place the components equally depending on the capacity state, but that is a wild guess…would need vSAN engineer input or a test